Transactions distribuées expliquées : 2 Phase Commit vs Saga Pattern
Tony Duong
juin 2, 2026 ・ 5 min
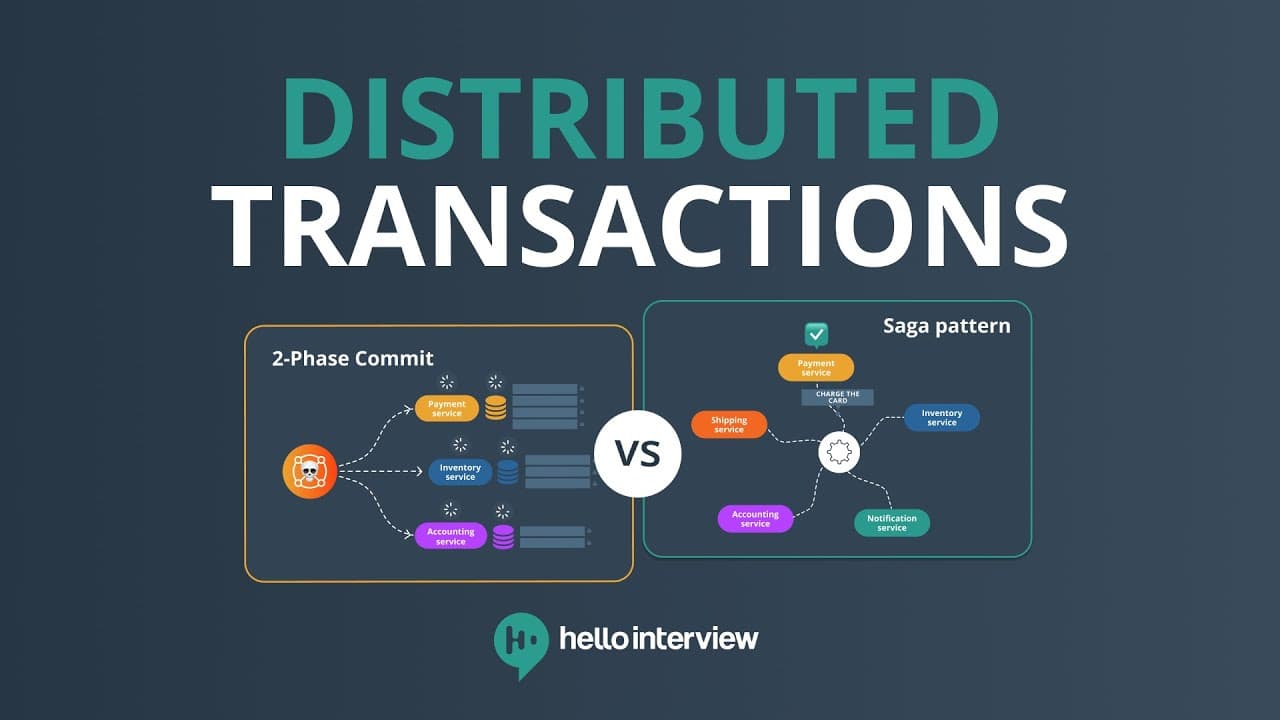
Notes de Hello Interview sur les transactions distribuées — ce qui change quand une base devient plusieurs, pourquoi le two-phase commit (2PC) fonctionne rarement entre services, et pourquoi l'industrie utilise Saga à la place.
Quand les transactions étaient simples
Au début, une seule base gère tout. Passer commande : débiter la carte, réserver le stock, enregistrer l'écriture comptable — le tout dans une transaction. Si une étape échoue, la DB annule automatiquement.
Garanties ACID pertinentes :
- Atomicité — les trois écritures réussissent ensemble, ou aucune
- Isolation — aucune autre requête ne voit un état à moitié terminé
Ce qui change quand on scale
Le trafic et les données augmentent. On shard la base ou on passe aux microservices — chaque service possède sa propre DB sur sa propre machine.
Le flux de paiement qui était une transaction devient trois opérations sur trois bases distinctes :
- Débiter la carte (DB paiement)
- Réserver le stock (DB inventaire)
- Enregistrer l'écriture (DB comptabilité)
Impossible d'envelopper une transaction entre bases indépendantes. Si le débit réussit mais la réservation échoue (rupture de stock), pas de rollback au niveau DB — le débit est déjà commité ailleurs.
C'est une transaction distribuée : une opération logique sur plusieurs bases/services où tout doit réussir ou être nettoyé.
Two-phase commit (2PC)
Solution académique classique. Introduire un coordinateur qui s'assure que tous les participants sont d'accord avant de rendre quoi que ce soit permanent.
Phase 1 — Prepare
Le coordinateur demande à chaque participant : « Peux-tu committer ? » Chaque DB fait le travail, enregistre durablement les changements, verrouille les lignes, et vote oui ou non.
- Un non → le coordinateur dit à tous d'abort et de libérer les verrous
- Tous oui → phase 2
Phase 2 — Commit
Le coordinateur envoie commit à tous. Les participants rendent les changements permanents et libèrent les verrous.
Avantage : cohérence forte — même garantie qu'une seule DB. Pas d'état partiel visible.
Pourquoi le 2PC échoue en production
Le 2PC est un protocole bloquant — dangereux en systèmes distribués car on dépend de plusieurs machines saines simultanément.
Crash du coordinateur : il collecte tous les oui, puis plante avant d'envoyer commit. Les participants restent avec des verrous, incapables de committer ou d'abort. Toute transaction touchant ces lignes est bloquée.
Autres problèmes :
- Le plus lent gagne — un service lent retient les verrous pour tous
- Partitions réseau — le coordinateur ne sait pas si le message est passé ; pas de défaut sûr
Réalité industrie : presque personne n'utilise le 2PC entre services indépendants. Pat Helland, dans Life Beyond Distributed Transactions, argue que les transactions distribuées entre services autonomes ne fonctionnent pas à l'échelle internet.
Le 2PC existe en production à l'intérieur de bases distribuées (Google Spanner, YugabyteDB) où coordinateur et participants sont couplés — la DB gère la complexité en interne. Entre services avec des calendriers de déploiement et des modes de panne différents, ça casse.
Pattern Saga
Ce qu'utilisent Uber, Netflix, Amazon et DoorDash en production.
Hypothèse différente : pas besoin d'atomicité tout-ou-rien entre services. Il faut éventuellement atteindre un état cohérent quand ça va mal.
Au lieu d'une grosse transaction distribuée avec verrous cross-services :
- Découper en une chaîne de transactions locales indépendantes
- Chaque service commit sur sa propre DB
- Quand une étape ultérieure échoue, exécuter des actions compensatoires (annulations métier) : remboursement au lieu de rollback
Compromis : cohérence éventuelle au lieu de forte. Le système peut être temporairement incohérent pendant les compensations (le client voit brièvement un débit avant le remboursement). Mais rien n'est bloqué.
Chorégraphie vs orchestration
Chorégraphie (décentralisée)
Publish/subscribe : chaque service diffuse un événement quand il a fini.
- Service carte débite → publie
CardCharged - Service inventaire écoute → réserve → publie
InventoryReserved - Service compta enregistre
- En cas d'échec, événement d'échec ; les services en amont compensent
Fonctionne pour des flux 2–3 étapes. À 5–6 services, tracer l'état devient pénible.
Orchestration (centralisée)
Un orchestrateur contrôle le flux étape par étape. En cas d'échec, il sait exactement quoi compenser et dans quel ordre.
Outils : Temporal, AWS Step Functions.
Différence clé avec le coordinateur 2PC : l'orchestrateur est durable. Au redémarrage, il reprend depuis sa DB — pas de verrous pendantants.
La plupart des équipes à grande échelle utilisent l'orchestration.
Actions compensatoires — la partie difficile
- Le remboursement est visible pour le client
- Certaines actions ne s'annulent pas : email envoyé, webhook tiers
- Les compensations peuvent échouer → logique de retry
- Les remboursements retentés doivent être idempotents
Problème du dual write et outbox transactionnel
Après le débit carte, le service doit sauver en DB et publier un événement — deux écritures séparées.
Correction : outbox transactionnel
- Écrire données et événement sortant dans la même DB en une transaction locale (table
outbox) - Processus en arrière-plan (CDC ou polling) publie vers le broker
Cadre de décision
D'abord : avez-vous vraiment besoin d'une transaction distribuée ?
Si les données qui transactent ensemble peuvent vivre dans la même base, faites-le. L'ACID local est plus simple et fiable.
Si vous ne pouvez pas éviter de distribuer
Utilisez une Saga.
| Situation | Choix |
|---|---|
| 3–4 étapes, services indépendants | Chorégraphie |
| Flux complexes, visibilité centralisée | Orchestration (Temporal, Step Functions) |
| Cohérence éventuelle inacceptable | DB distribuée unique (Spanner, YugabyteDB) — pas de DIY 2PC |
Pattern production à l'échelle
Saga avec orchestration + opérations idempotentes + outbox transactionnel.
Points clés
- L'ACID mono-DB casse quand chaque service possède sa base
- Le 2PC donne la cohérence forte mais bloque
- Saga = commits locaux + compensations
- Outbox transactionnel pour éviter le dual write
- Meilleure réponse quand possible : ne pas distribuer la transaction
🌐 Traduit par Claude
