Entretien system design : concevoir Twitter
Tony Duong
juin 3, 2026 ・ 3 min
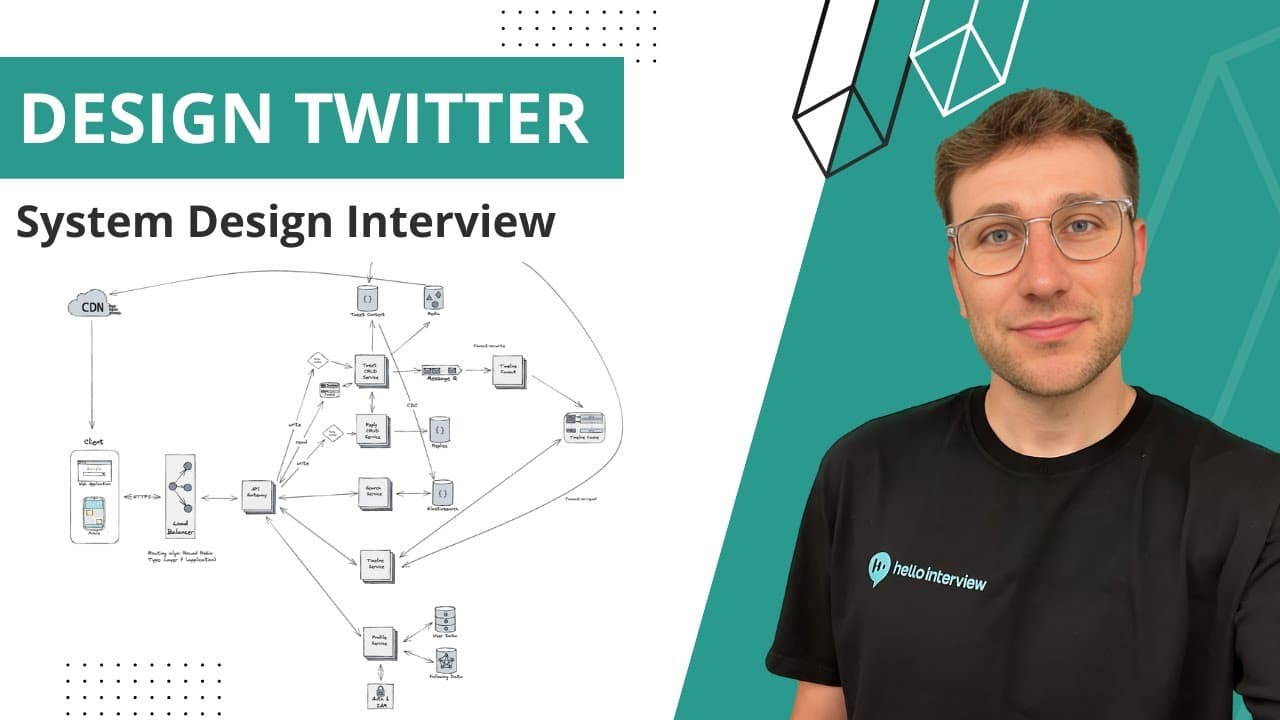
Notes Hello Interview (ex Meta staff engineer) sur la conception d'un service type Twitter — l'une des questions d'entretien system design les plus fréquentes chez les FAANG.
Exigences (moins de 5 minutes)
Fonctionnelles
- Compte / login
- CRUD tweets
- Follow
- Timeline d'accueil
- Like, reply, retweet
- Recherche
Non-fonctionnelles
- Centaines de millions de DAU
- Volume élevé de créations et lectures
- 99,99 % de disponibilité
- Sécurité et confidentialité
- Très faible latence au chargement
Hors scope : DM, pubs, intégrité — 45 minutes, pas 17 ans.
Architecture
Client → Load balancer couche 7 (round robin) → API Gateway → microservices.
Services clés
| Service | Rôle |
|---|---|
| Tweet CRUD | Tweets, likes, retweets |
| Reply | Réponses (scalées à part) |
| Search | Recherche |
| Timeline | Fil d'accueil |
| Profile | Comptes, graphe social |
| Auth | Authentification |
Stockage tweets — pourquoi NoSQL
Twitter utilise Manhattan (NoSQL interne). En entretien : MongoDB.
Pourquoi NoSQL pour les tweets :
- Read/write intensifs à très faible latence
- Tweet = document JSON autonome — pas de joins complexes
- Lire un tweet = retourner un document
Médias : S3 ; le document tweet ne garde que des références.
Timeline
Fan-out on read (naïf)
Requête → comptes suivis → tous les tweets → tri. Lent — échoue la NFR latence.
Fan-out on write (préféré)
- Tweet dans une file de messages
- Workers récupèrent les followers
- Préfixer le tweet dans le cache timeline de chaque follower (Redis-like)
Lecture = données déjà prêtes → lectures ultra-rapides.
Mega influencers (hybride)
Millions de followers : fan-out on write peut submerger le système.
- Utilisateurs moyens : fan-out on write
- Célébrités : fan-out on read à l'ouverture du fil
Profil et graphe social
| Données | Stockage | Pourquoi |
|---|---|---|
| Profils utilisateur | SQL | Attributs structurés, ACID, analytics |
| Graphe followers | Graph DB | Réseaux sociaux, recommandations |
Auth isolé pour la sécurité.
Recherche
Elasticsearch + CDC depuis le store de tweets.
CDN, sécurité, monitoring
CDN pour médias. HTTPS, chiffrement au repos, rate limiting, validation d'entrée. Prometheus/Grafana, ELK, alertes.
Quand le NoSQL est le bon outil
Pour des chemins read/write intensifs à très faible latence et des accès simples (document par ID, sans joins), les stores document NoSQL conviennent souvent.
SQL pour l'intégrité relationnelle. Graph DB pour les relations. Moteur de recherche + CDC pour le full-text. Cache + queue pour la timeline.
Points clés
- Tweet CRUD → NoSQL document
- Timeline → fan-out on write + cache ; hybride pour mega influencers
- Graphe → graph DB ; utilisateurs → SQL
- Adapter le stockage au pattern d'accès
🌐 Traduit par Claude
