Vertex AI Gen AI evaluation in the Google Cloud console
Tony Duong
Mar 29, 2026 ・ 2 min

The Gen AI evaluation service on Vertex AI lets you run datasets through one or more models and score outputs with rubric-based metrics (including adaptive rubrics), deterministic scores where you have ground truth, or custom logic in code. Below is a real console run: gemini-1.5-flash as a single candidate, evaluated with General Quality, on prompts that ask the model to turn a recipe into a categorized shopping list.
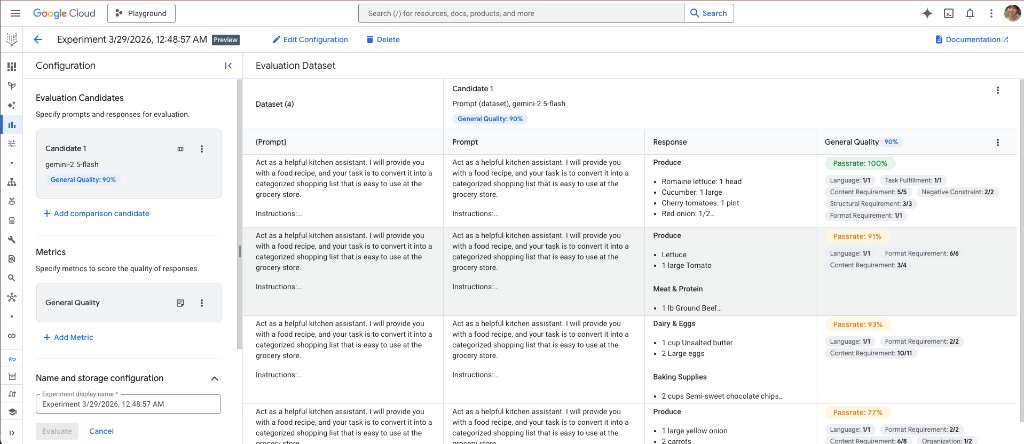
What the UI shows
- Left: configuration for Candidate 1 (here gemini-1.5-flash) and the selected metric (General Quality), with an overall score (90% in this experiment).
- Right: the evaluation dataset table: each row has the prompt (kitchen-assistant instructions plus the recipe), the model response (e.g. sections such as Produce, Meat & protein, Dairy & eggs, Baking supplies), and a per-row breakdown. General Quality is decomposed into dimensions such as language, task fulfillment, content / structure / format requirements, and negative constraints, with a pass rate per row (100%, 91%, 93%, 77% in the visible rows).
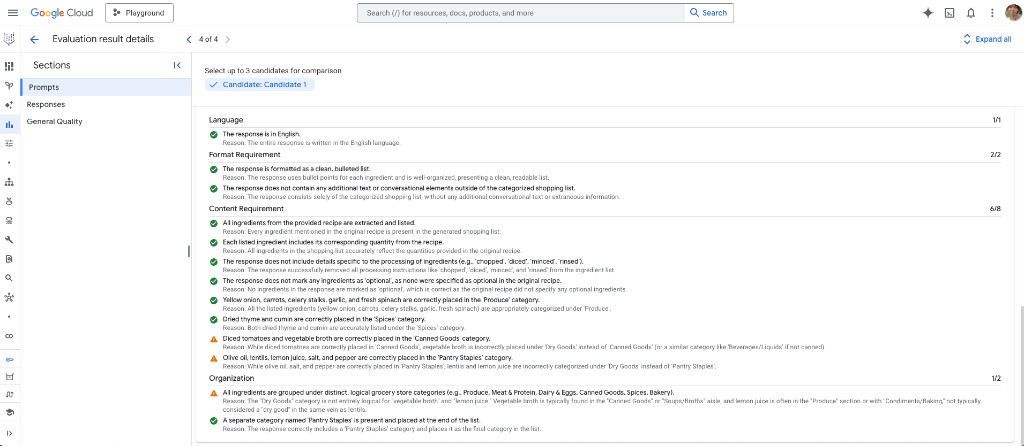
Evaluation result details (drill-down)
Opening a row shows Evaluation result details: rubric line items with Pass / Fail, short Reason text, and section scores (e.g. Language 1/1, Format requirement 2/2, Content requirement 6/8, Organization 1/2). In this run the judge accepted English, a clean bullet-only list, and most ingredient extraction rules, but flagged mis-categorized items (e.g. vegetable broth under Dry goods instead of Canned goods, lentils and lemon juice not under Pantry staples)—exactly the kind of granular feedback you use to tighten prompts or post-process outputs.
For a minimal YAML → generate → evaluate workflow outside the console, see the Ruby harness tonystrawberry/ruby-vertex-eval (aligned with the same mental model: managed metrics via evaluateInstances, not the Python SDK’s adaptive general_quality_v1 rubric path).
References
- Gen AI evaluation service overview (Google Cloud Documentation)
- tonystrawberry/ruby-vertex-eval on GitHub
