Évaluation Gen AI Vertex AI dans la console Google Cloud
Tony Duong
mars 29, 2026 ・ 3 min

Le service d’évaluation Gen AI sur Vertex AI permet de faire passer des jeux de données dans un ou plusieurs modèles et de noter les sorties avec des métriques basées sur des rubriques (y compris des rubriques adaptatives), des scores déterministes lorsque vous avez une vérité terrain, ou une logique personnalisée en code. Ci-dessous : une exécution réelle dans la console : gemini-1.5-flash comme seul candidat, évalué avec General Quality, sur des prompts qui demandent de transformer une recette en liste de courses catégorisée.
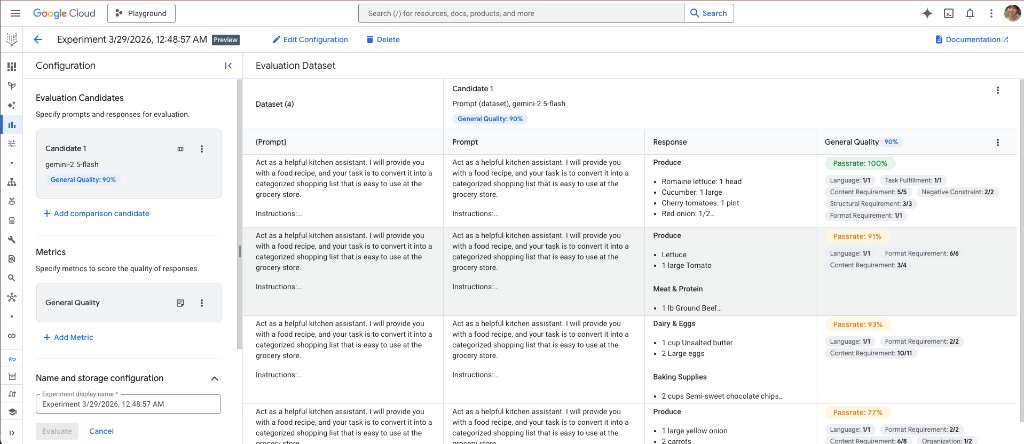
Ce que montre l’interface
- À gauche : configuration du Candidate 1 (ici gemini-1.5-flash) et de la métrique choisie (General Quality), avec un score global (90 % dans cette expérience).
- À droite : le tableau du jeu d’évaluation : chaque ligne contient le prompt (instructions d’assistant cuisine + recette), la réponse du modèle (ex. sections Produce, Meat & protein, Dairy & eggs, Baking supplies) et un détail par ligne. General Quality se décompose en dimensions comme la langue, le respect de la tâche, les exigences de contenu / structure / format et les contraintes négatives, avec un taux de réussite par ligne (100 %, 91 %, 93 %, 77 % sur les lignes visibles).
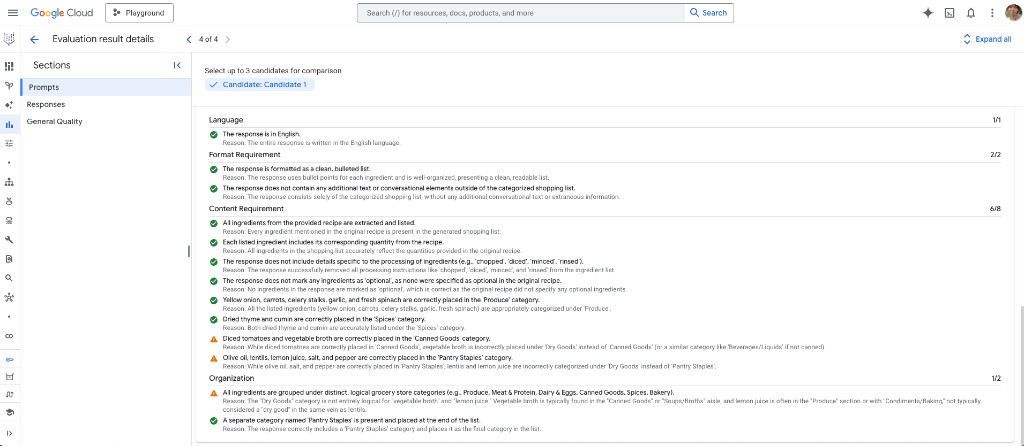
Détails des résultats d’évaluation (zoom)
En ouvrant une ligne, on obtient Evaluation result details : éléments de rubrique avec Pass / Fail, texte de Reason court, et scores par section (ex. Language 1/1, Format requirement 2/2, Content requirement 6/8, Organization 1/2). Dans ce run, le juge a accepté l’anglais, une liste à puces sans texte superflu, et la plupart des règles d’extraction d’ingrédients, mais a signalé des mauvaises catégories (ex. bouillon de légumes sous Dry goods au lieu de Canned goods, lentilles et jus de citron absents de Pantry staples) — le type de retour fin qui sert à resserrer les prompts ou le post-traitement.
Pour un flux minimal YAML → génération → évaluation hors console, voir le squelette Ruby tonystrawberry/ruby-vertex-eval (même idée : métriques managées via evaluateInstances, pas le chemin de rubrique adaptative general_quality_v1 du SDK Python).
Références
- Gen AI evaluation service overview (documentation Google Cloud)
- tonystrawberry/ruby-vertex-eval sur GitHub
🌐 Traduit par Claude
