Google Cloud コンソールでの Vertex AI Gen AI 評価
Tony Duong
3月 29, 2026 ・ 1 分

Vertex AI の Gen AI 評価サービスでは、データセットを 1 つ以上のモデルに通し、ルーブリックに基づくメトリクス(適応型ルーブリックを含む)、正解がある場合の決定的スコア、またはコードによる独自ロジックで出力を採点できます。以下は実際のコンソール実行です。gemini-1.5-flash を単一候補とし、General Quality で評価。プロンプトはレシピをカテゴリ分けした買い物リストに変換する内容です。
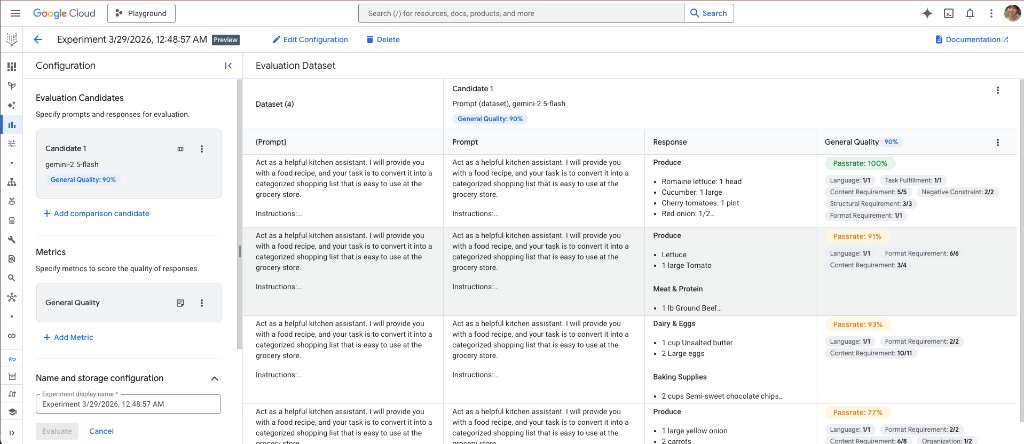
UI の見方
- 左: Candidate 1(ここでは gemini-1.5-flash)と選択したメトリクス(General Quality)の設定、および全体スコア(この実験では 90%)。
- 右: 評価データセット表。各行にプロンプト(キッチンアシスタントの指示+レシピ)、モデルの回答(例:Produce、Meat & protein、Dairy & eggs、Baking supplies などのセクション)、行ごとの内訳。General Quality は言語、タスク充足、コンテンツ/構造/形式の要件、ネガティブ制約などに分解され、行ごとに合格率(表示行では 100%、91%、93%、77%)が付きます。
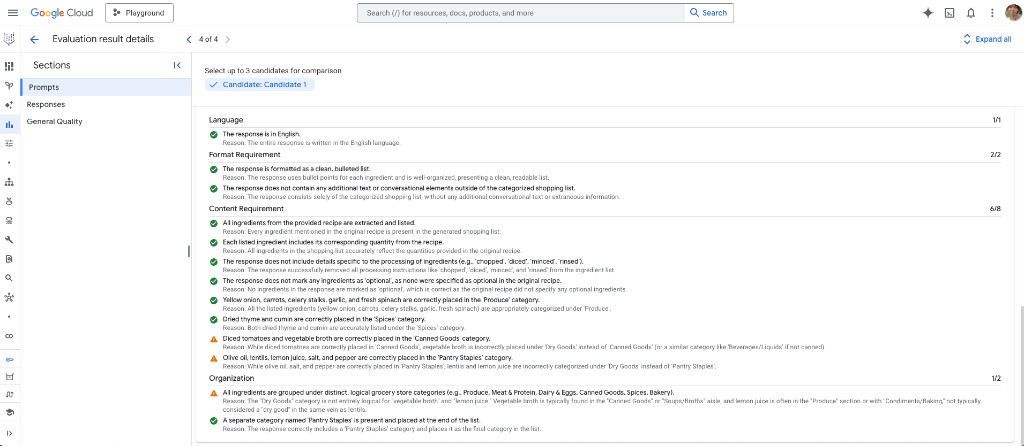
評価結果の詳細(ドリルダウン)
行を開くと Evaluation result details が表示され、ルーブリック項目ごとに Pass / Fail、短い Reason、セクションスコア(例:Language 1/1、Format requirement 2/2、Content requirement 6/8、Organization 1/2)が確認できます。この実行では英語・箇条書きのみのきれいなリスト・ほとんどの材料抽出ルールは通過しましたが、誤分類(例:野菜ブイヨンが Canned goods ではなく Dry goods、レンズ豆とレモン汁が Pantry staples にない)が指摘されています。プロンプトや後処理を詰めるのに使える粒度のフィードバックです。
コンソール外で最小の YAML → 生成 → 評価 フローを試す場合は Ruby の tonystrawberry/ruby-vertex-eval を参照(同じ考え方:evaluateInstances によるマネージドメトリクス。Python SDK の適応型 general_quality_v1 ルーブリック経路ではない)。
参考
- Gen AI evaluation service overview(Google Cloud ドキュメント)
- GitHub の tonystrawberry/ruby-vertex-eval
🌐 Claudeによる翻訳
